.NET 8 performance: Dictionary vs. FrozenDictionary
With .NET 8 we are introduced to a new dictionary type which improves the performance of read operations. The catch: you are not allowed to make any changes to the keys and values once the collection is created. This type is particularly useful for collections that are populated on first use and then persisted for the duration of a long-lived service.
Let’s have a look at what this means in numbers. I am interested in two things:
- dictionary creation performance – the work done for read optimization is likely to have an impact on this
- read performance for a random key in the list
Performance impact on creation
For this test, we take 10.000 pre-instantiated KeyValuePair<string, string> and create three different types of dictionaries:
- a normal dictionary:
new Dictionary(source) - a frozen dictionary:
source.ToFrozenDictionary(optimizeForReading: false) - and a frozen dictionary which is optimized for reading:
source.ToFrozenDictionary(optimizeForReading: true)
And we benchmark how long each of these operations take using BenchmarkDotNet. These are the results:
| Method | Mean | Error | StdDev |
|------------------------------------ |-----------:|---------:|---------:|
| Dictionary | 284.2 us | 1.26 us | 1.05 us |
| FrozenDictionaryNotOptimized | 486.0 us | 4.71 us | 4.41 us |
| FrozenDictionaryOptimizedForReading | 4,583.7 us | 13.98 us | 12.39 us |Code language: JavaScript (javascript)Already, with no optimization, we can see that creating the FrozenDictionary takes about twice as much as it takes to create the normal dictionary. But the real impact comes when optimizing the data for read. In this scenario, we get a 16x increase. So is this worth it? How fast is the read?
Frozen dictionary read performance
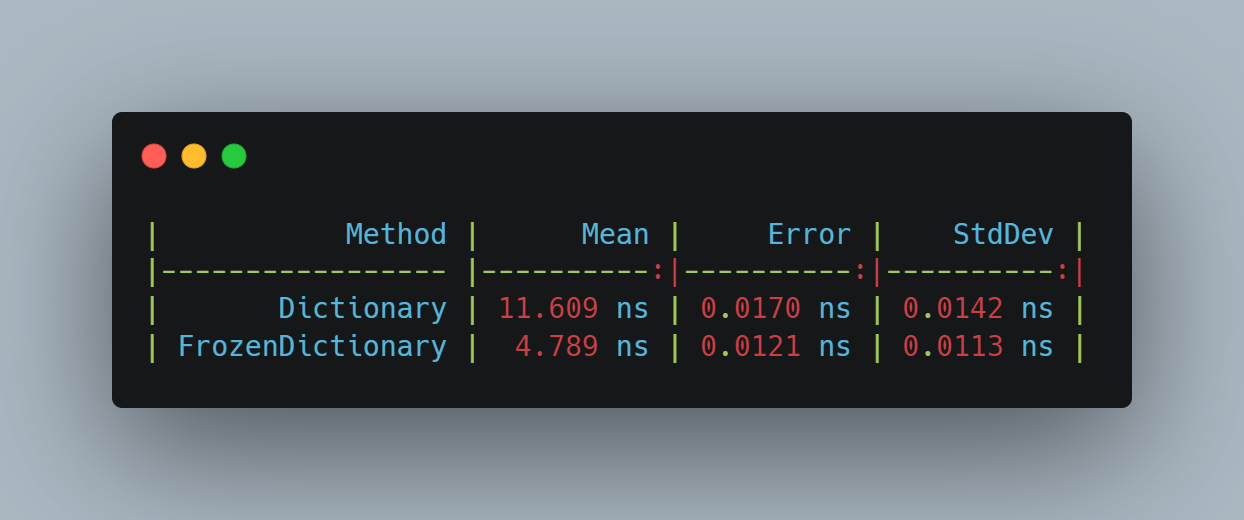
In this first scenario, where we test retrieving a single key from the ‘middle’ of the dictionary, we get the following results:
| Method | Mean | Error | StdDev |
|------------------------------------ |----------:|----------:|----------:|
| Dictionary | 11.609 ns | 0.0170 ns | 0.0142 ns |
| FrozenDictionaryNotOptimized | 10.203 ns | 0.0218 ns | 0.0193 ns |
| FrozenDictionaryOptimizedForReading | 4.789 ns | 0.0121 ns | 0.0113 ns |Code language: JavaScript (javascript)In essence, the FrozenDictionary seems to be 2.4x faster than the normal Dictionary. Quite an improvement!
One important thing to note, is the different unit of measures here. For the creation, the times are in the microsecond range, and in total we lose about 4299 us (microseconds). That, converted to ns (nanoseconds) means 4299000 ns. That means, that in order to have a performance benefit from using the FrozenDictionary we’d have to do at least 630351 read operations on it. That’s a lot of reads to have to make.
Let’s take a couple more test scenarios and see what impact they have on performance.
Scenario 2: Small dictionary (100 items)
The multiples seem to stay the same when dealing with a smaller dictionary. In terms of cost benefit, we seem to be profiting a little earlier – after about 4800 read operations.
| Method | Mean | Error | StdDev |
|------------------------------------------- |----------:|----------:|----------:|
| Dictionary_Create | 1.477 us | 0.0033 us | 0.0028 us |
| FrozenDictionaryOptimizedForReading_Create | 31.922 us | 0.1346 us | 0.1259 us |
| Dictionary_Read | 10.788 ns | 0.0156 ns | 0.0122 ns |
| FrozenDictionaryOptimizedForReading_Read | 4.444 ns | 0.0155 ns | 0.0129 ns |Code language: JavaScript (javascript)Scenario 3: Read keys from different positions
In this scenario we test if the performance is in any way impacted by the key we are retrieving (where it’s positioned in the internal data structure). And based on the results, it has no impact whatsoever on the read performance.
| Method | Mean | Error | StdDev |
|------------------------------------------- |----------:|----------:|----------:|
| FrozenDictionaryOptimizedForReading_First | 4.314 ns | 0.0102 ns | 0.0085 ns |
| FrozenDictionaryOptimizedForReading_Middle | 4.311 ns | 0.0079 ns | 0.0066 ns |
| FrozenDictionaryOptimizedForReading_Last | 4.314 ns | 0.0180 ns | 0.0159 ns |Code language: JavaScript (javascript)Scenario 4: Large dictionary (10 million items)
In the case of large dictionaries, the read performance remains almost the same. We see an 18% increase in read time, despite a 1000x increase in dictionary size. However, the target number of reads needed to have a net performance gain goes up significantly, to 2,135,735,439 – that’s over 2 billion reads.
| Method | Mean | Error | StdDev |
|------------------------------------------- |------------:|----------:|----------:|
| Dictionary_Create | 905.1 ms | 2.56 ms | 2.27 ms |
| FrozenDictionaryOptimizedForReading_Create | 13,886.4 ms | 276.22 ms | 483.77 ms |
| Dictionary_Read | 11.203 ns | 0.2601 ns | 0.3472 ns |
| FrozenDictionaryOptimizedForReading_Read | 5.125 ns | 0.0295 ns | 0.0230 ns |Code language: JavaScript (javascript)Scenario 5: Complex key
Here the results are very interesting. Our key looks like this:
public class MyKey
{
public string K1 { get; set; }
public string K2 { get; set; }
}
Code language: C# (cs)And as we can see, there is almost no peformance improvements on the read in this case compared to the normal Dictionary, while the dictionary creation is about 4 times slower.
| Method | Mean | Error | StdDev |
|------------------------------------------- |---------:|----------:|----------:|
| Dictionary_Create | 247.7 us | 3.27 us | 3.05 us |
| FrozenDictionaryOptimizedForReading_Create | 991.2 us | 8.75 us | 8.18 us |
| Dictionary_Read | 6.344 ns | 0.0602 ns | 0.0533 ns |
| FrozenDictionaryOptimizedForReading_Read | 6.041 ns | 0.0954 ns | 0.0845 ns |Code language: JavaScript (javascript)Scenario 6: Using records
But what if we used a record instead of a class? That ought to offer more performance, right? Apparently not. It’s even more strange as the read times jump from 6 ns to 44 ns.
| Method | Mean | Error | StdDev |
|------------------------------------------- |-----------:|---------:|---------:|
| Dictionary_Create | 654.1 us | 2.29 us | 2.14 us |
| FrozenDictionaryOptimizedForReading_Create | 1,761.4 us | 8.67 us | 8.11 us |
| Dictionary_Read | 45.37 ns | 0.088 ns | 0.082 ns |
| FrozenDictionaryOptimizedForReading_Read | 44.44 ns | 0.120 ns | 0.107 ns |Code language: JavaScript (javascript)Conclusions
Based on the tested scenarios, the only improvement we saw was when using string keys. Anything else we tried thus far, has led to the same read performance as the normal Dictionary, with an added overhead on creation.
Even when using strings as your FrozenDictionary key, you have to consider how many reads you’re going to make in the lifetime of that dictionary as there is an overhead associated with the creation of the dictionary. In the 10.000 items test, that overhead was of about 4299000 ns. The read performance saw a 2.4x improvement, with a drop from 11.6 ns to 4.8 ns, but this still means that you need roughly 630351 read operations on the dictionary before you have a net performance gain.

The perf hit with records comes from the record generated code.
Normally, GetHashcode is overridden for types. For the custom type usage before the record version, that uses a RuntimeHelpers.GetHashCode – basically a hash associated with that instance’s allocation. Then it uses object.ReferenceEquals, in case of hash collision -> bucket traversal. It doesn’t care about the fields you declared. You can probably make it as slow as record by manually overiding GetHashCode and Equals.
For the record type, it has to compute the combined hashcode, so it has multiple calls to hashcode (toplevel + each field), sometimes even recursively. On hash collision, you end up with some more overhead, since structural equality has to compare all the fields themselves.
Since you have 3 pointer accesses at least in the record type (key, field1, field2 – GetHashCode and Equals) depending on how the strings are initialized, that might lead to cache misses. Using something like a primitive might reduce the numbers a bit, but it would still possibly try to hash each primitive.
The numbers might improve quite a bit if IEquatable is implemented on your type and caching any hashcode if types are immutable.
Hope this sheds some light into why the numbers go up.
Hi Marius. Thanks for the nice post. Did you measure the performance again with .NET release? It would be nice to see if something has changed, or do you have the code to share?